Published on: May 9, 2025
by: Velocity Capital
Monad — the Fastest EVM L1 Ever Built
Since launching its public testnet in February, Monad, a high-performance, EVM-compatible Layer 1 blockchain built from scratch in C++ and Rust, has processed over 1 billion transactions, hit 500ms block times, achieved 1-second finality, and pushed beyond 10,000 transactions per second (TPS) — all while running a globally distributed validator set of 99**+ nodes**. With 300 million gas/sec throughput live today and plans to scale to 1 billion by mainnet, there are 4 pillars empowering such a performance, while preserving full EVM bytecode equivalence and Ethereum RPC compatibility:
- MonadBFT: A pipelined HotStuff-inspired consensus protocol offering 500ms block times and 1s finality, with tail-forking resistance and linear message complexity.
- Asynchronous Execution: Execution is decoupled from consensus, removing bottlenecks and allowing the network to utilize the full block time for both.
- Optimistic Parallel Execution: Transactions are run in parallel with optimistic execution and validated in serial order, enabling massive throughput without compromising determinism.
- MonadDB: A custom state storage backend purpose-built for speed and parallelism, enabling fast, efficient Merkle trie access.
This article will break down exactly how Monad works under the hood — from pipelined parallel execution to MonadBFT and MonadDB — and why it could redefine blockchain scalability and reshape the modular vs. monolithic debate for good.
-
How Monad’s BFT Consensus Delivers Speed and Scale
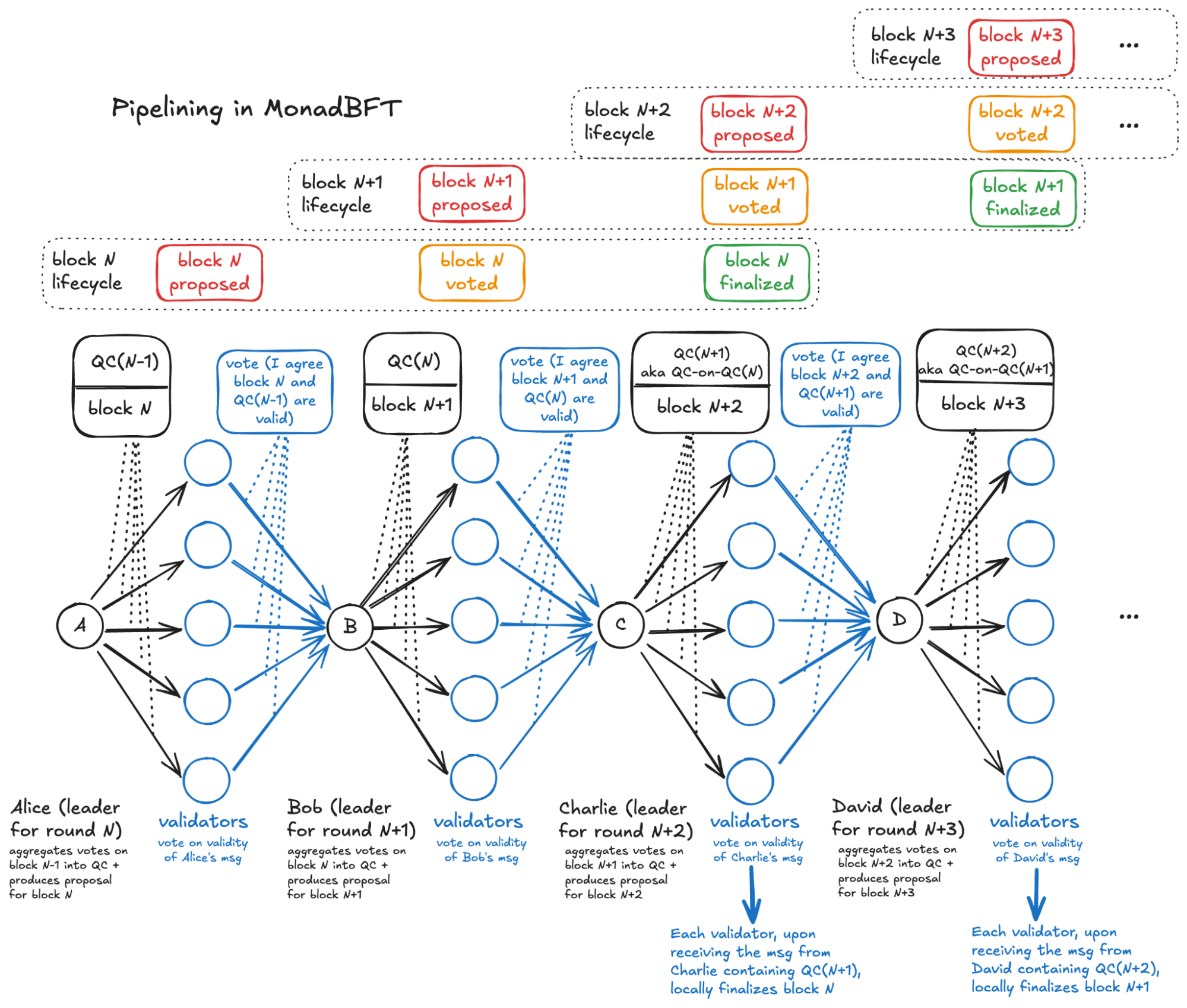
Image 1
At the heart of Monad’s speed and reliability lies its custom-built consensus protocol: MonadBFT. Designed for scalability and speed, it enables hundreds of globally distributed validators to participate directly in consensus — all while maintaining low latency and high throughput.
Fan-Out / Fan-In Voting
In MonadBFT, the fan-out/fan-in structure underpins block production and finality:
- A leader node (e.g. Alice) proposes a block and broadcasts it to all other validators.
- Validators individually verify the block and send their votes to the next scheduled leader (e.g. Bob).
- Bob then aggregates these votes into a quorum certificate (QC) — a cryptographic proof that a supermajority agreed on the block.
- Bob then fans out the QC to all validators again, preparing the network for the next round.
- The next leader (e.g. Charlie) repeats the process: generating a QC-on-QC to confirm finality for Alice’s original block and preparing QC for Bob’s block while proposing his own block
This loop allows every new leader to certify the previous block and propose their own block parallelly, forming a continuous chain of cryptographic validation that supports secure, decentralized block production at scale.
Pipelining QCs with Block Proposals
In a typical BFT system, validators finalize one block and only then begin working on the next. Monad has changed by pipelining QCs with block proposals, further enhancing throughput so that every leader sends out a QC and a new block at the same time.
For example:
- When Bob aggregates votes from validators into a QC to confirm Alice’s block, he also includes his own new block proposal.
- Then Charlie does the same — confirming Bob’s QC while pushing out the next block — and so on.
This means that every tick of the consensus process includes a new block, turning the whole system into a continuous, overlapping pipeline.
Think of it like an assembly line — while one task is finishing, the next is already starting. This eliminates wait time and significantly boosts throughput.
By embedding block proposals directly into the consensus flow, Monad ***minimizes idle time and transforms each round of consensus into a high-performance cycle, without compromising decentralization.
Efficient Block Propagation: Introducing RaptorCast
In MonadBFT, block proposers like Alice broadcast blocks containing thousands of transactions to all other validators, but with 10,000 transactions at ~200 bytes each — the total size can exceed 2 MB per block. The issue is, if Alice has to send this 2 MB block to every validator in a globally distributed network of 200 validators, that’s 400 MB of outbound data, or 3.2 Gbps of upload bandwidth — just for one block! That level of throughput requirement simply isn’t viable for a decentralized network.
To address this, Monad introduces RaptorCast — a custom multicast algorithm purpose-built for fast, fault-tolerant, and efficient large block distribution at scale.
Here’s how it works:
- The block is split into small, fixed-size chunks using erasure coding — each chunk carries 1220 bytes of payload, with an additional 260 bytes for headers (based on the Maximum Transmission Unit (MTU) of 1480 bytes). For example, a 2 MB block becomes ~1640 source chunks. Applying the default 2× redundancy, this yields 3280 encoded chunks — meaning any ~1640 of them are sufficient to reconstruct the full block. This redundancy adds fault tolerance and avoids the need for retransmissions.
- Here's the breakdown:
- MTU = 1480 bytes; header overhead = 260 bytes
- ⇒ Remaining payload per chunk = 1220 bytes
- So:
- 2,000,000 bytes / 1220 bytes ≈ 1640 source chunks (these are the minimum needed to reconstruct the original block)
- But then, RaptorCast applies a redundancy factor of 3, meaning 1640 source chunks × 2 = 3280 encoded chunks; this redundancy helps withstand packet loss or faulty validators.
- Out of the 3280 encoded chunks, any subset of ~1640 chunks is sufficient to reconstruct the full 2 MB block — you don’t need all 3280. This is the power of erasure coding: it creates fault-tolerant data.
- This is also why RaptorCast doesn’t use retransmission protocols like TCP — it’s UDP-based, fast and robust by design through this redundancy.
- Here's the breakdown:
- Chunks are assigned to validators proportionally to their stake weight. So while chunk size remains the same (~1220 bytes), validators with more stake are assigned more chunks to relay as “first-hop” broadcasters in a two-level tree. For example, if all 99 validators have equal stake, each gets ~50 chunks. If one has double the stake, they get double the chunk load — ensuring fair bandwidth usage and robust delivery across the network.
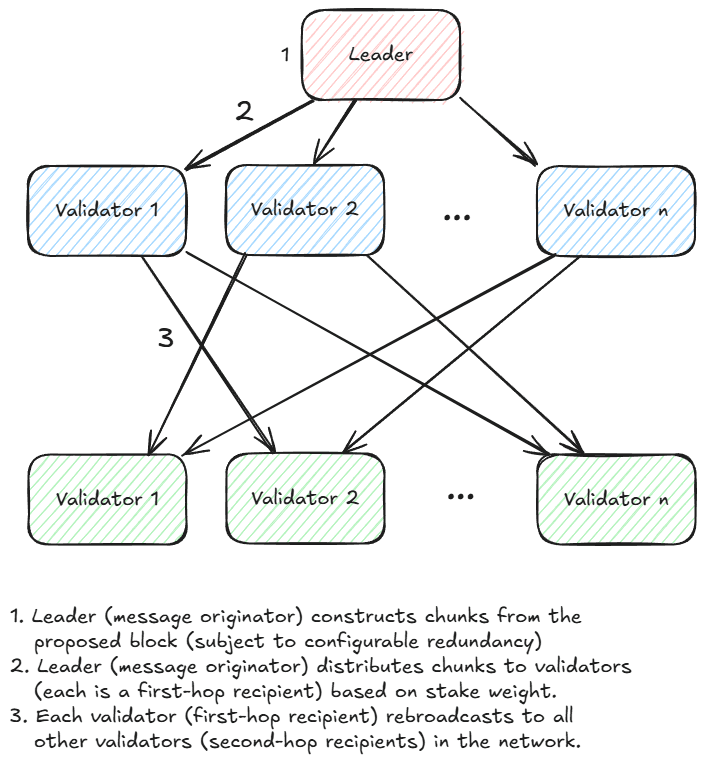
- Validators validate chunk integrity via Merkle root signatures. RaptorCast sends chunks using UDP (User Datagram Protocol), a fast and lightweight way to send data without any need of confirmations. And because some chunks might get lost along the way, RaptorCast adds redundancy by sending extra chunks so the block can still be reconstructed without needing to resend anything.
- Unlike TCP, it doesn’t require acknowledgments or retransmissions, so it’s quicker and makes it ideal for speed-critical systems like RaptorCast
Even if up to 33% of validators fail to forward their chunks, the block can still be reconstructed thanks to erasure coding and the 2x redundancy factor.
RaptorCast ensures fast, decentralized block propagation with ***minimal bandwidth strain on the proposer — making large block distribution practical, even at Monad’s scale.
Mitigation of Tail-forking
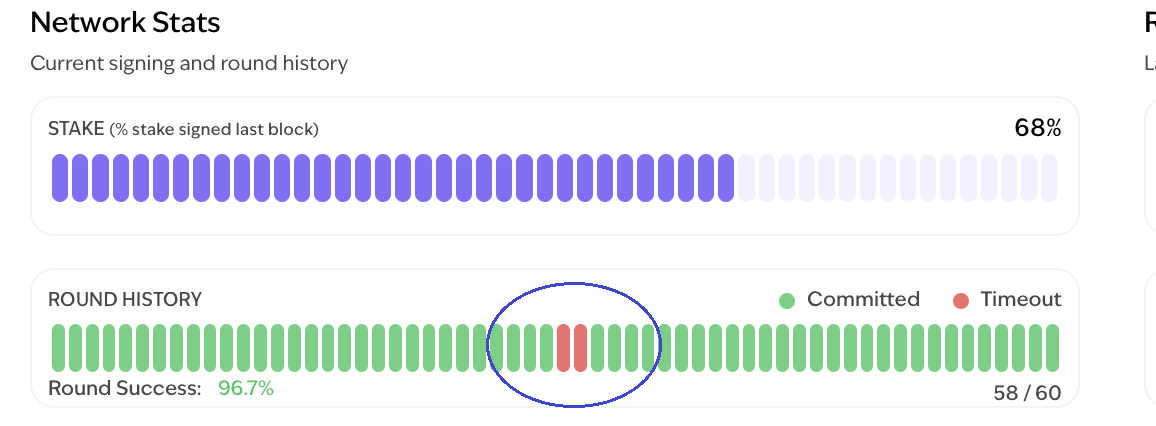
Let’s start with the problem MonadBFT solves — tail-forking, a flaw in traditional pipelined HotStuff protocols where a valid block may be dropped if the next leader fails to include it. This isn’t just a minor hiccup — it causes honest validators to lose rewards, enables multi-block MEV attacks, degrades UX for latency-sensitive applications, and can escalate into broader network instability.
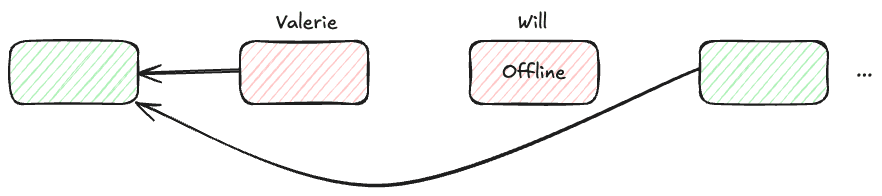
A real example of this happened on the Monad testnet: validator Valerie proposed a valid block, but it wasn’t finalized because the next leader, Will, was offline. Even though Valerie did everything right, her block was discarded, and she earned nothing. Worse, if validators like Will and the next leader (say, Xander) are malicious, they can collude — Will drops the block on purpose, and Xander re-proposes it, rearranging transactions to extract MEV.
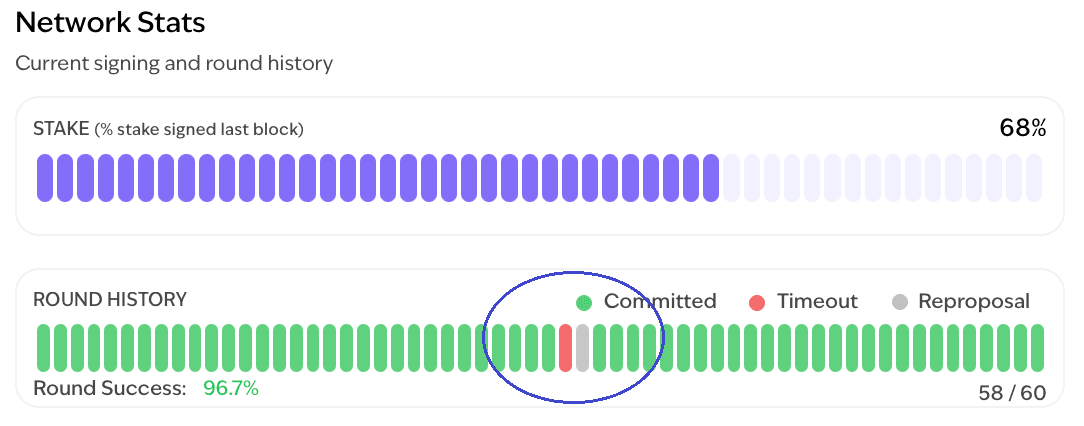
MonadBFT redesigns the pipeline. It ensures that any block with sufficient honest votes must eventually be finalized, even if the next leader goes offline or is malicious. This is done through a system of Fresh Proposals, Reproposals, and NECs (No Endorsement Certificates). If a prior block wasn’t finalized, the new leader must either repropose it or present a cryptographic proof (NEC) that it was never received. This keeps the chain in sync, fair, and resilient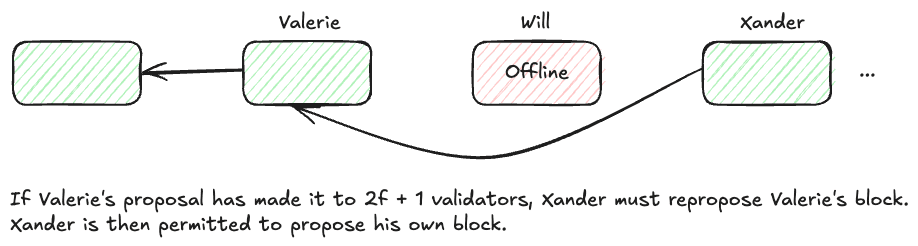
In doing so, MonadBFT introduces four standout properties:
- Tail-forking resistance: No more abandoned valid blocks. Honest validators get their proposals finalized.
- Speculative finality: Blocks can be considered final ~500ms after proposal if no malicious behavior is detected — unlocking responsive UX.
- Optimistic responsiveness: Consensus progresses as fast as the network allows — no artificial timeouts.
- Linear communication complexity: With fan-out/fan-in voting and erasure coding, the protocol remains scalable even with large validator sets.
Back to our real example—Valerie, Will, and Xander:
Earlier, we discussed a common failure in pipelined BFT systems. Valerie, an honest validator, proposes a valid block. But when the next leader, Will, goes offline and fails to finalize Valerie’s proposal, her work is discarded—even though she followed the protocol correctly.
Now, let’s replay this scenario under MonadBFT:
Valerie proposes her block. Will is still offline. But the next leader, Xander, now operates under MonadBFT rules. Instead of discarding Valerie’s block:
- Xander first reproposes Valerie’s block, ensuring it gets finalized.
- Only after that does Xander propose his own block.
Fairness is restored — Valerie’s block is preserved, rewards are retained, and network continuity is maintained. This also means that even if a validator goes offline, previous valid work isn’t lost, and malicious tail-forking for MEV becomes significantly harder to execute.
This example illustrates how MonadBFT enforces fairness and strengthens the chain’s resilience — making sure honest validators aren't penalized for others’ failures and that the protocol doesn’t leave room for exploitative reorgs.
-
Asynchronous Execution: Scaling Without Bottlenecks
Most blockchains tightly interleave consensus and execution — the leader must execute all transactions before proposing a block, and validators must do the same before voting. This means execution happens twice per block, in a very short window. On Ethereum, for instance, only ~100ms of the 12-second block time is effectively used for computation — less than 1%; most of the time is for reaching consensus!

Monad takes a different approach. With asynchronous execution, Monad decouples consensus from execution entirely. Validators agree on the order of transactions first, and execution takes place simultaneously after consensus. This allows ***both execution and consensus to run in parallel — so execution can use the full block time without slowing down consensus.
How It Works
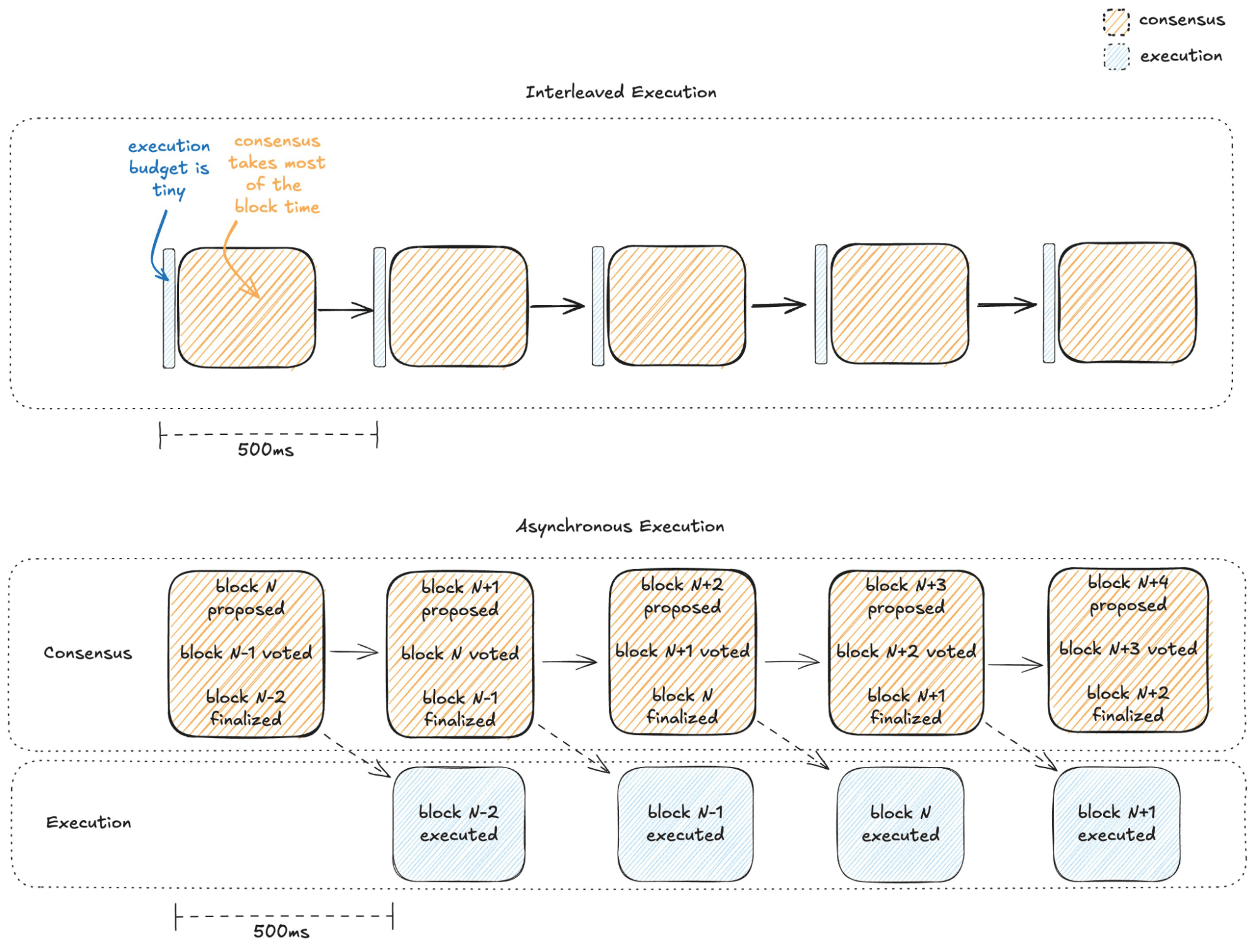
- At slot N, the leader proposes block N.
- At slot N+1, validators aggregate votes of block N into a quorum certificate (QC) and fan out the QC to all validators again, together with the proposal of block N+1. (soft finality) Speculative execution may take place where execution starts proceeding under the assumption that the block will most likely be finalized
- At slot N+2, the block is fully finalized — only then validators commit the output — i.e., they finalize the resulting state (balances, storage updates, etc.) from executing Block N.
By this point, the order of transactions is locked in, and nodes can now safely execute the block to update state.
To keep things fast and responsive:
- Consensus comes first: Validators agree on the transaction order during consensus, but they do not execute transactions at this stage — only the ordering is finalized (see Image 1).
- Speculative execution begins after soft finality: Once a Quorum Certificate (QC) for Block N is available — meaning a supermajority of validators have voted for it (also illustrated in Image 1) — validators may begin executing those transactions even though the block isn’t strictly finalized yet. This stage is known as speculative finality, where execution proceeds under the assumption that the block will most likely be finalized.
- Execution finalizes the state: When the block reaches full finality (typically at Block N+2, when a QC-on-QC is included for Block N), the output of execution is confirmed and committed — updating the blockchain state (balances, contract storage, etc.).
By decoupling consensus and execution, and leveraging speculative execution under soft finality, Monad allows both processes to fully utilize the block time in parallel. This architecture delivers higher throughput, lower latency, and a smoother developer and user experience. In fact, Ethereum is also trying to implement something similar now after Monad pioneers this approach.
Delayed Merkle Root
Because execution happens after consensus, Monad block proposals don’t include the immediate state root. Instead, each block includes a delayed Merkle root from D blocks ago (currently 3), allowing nodes to detect divergence and re-sync if needed. If a node miscomputes, it can roll back and re-execute to fix its local state.
Preventing DoS with Balance Tracking
Even though execution is delayed, validators still enforce a basic validity check: ensuring the sender can pay for the transaction. This is done by tracking each account’s available balance in real time during consensus — blocking spam transactions before they even reach the execution stage.
Block States Overview
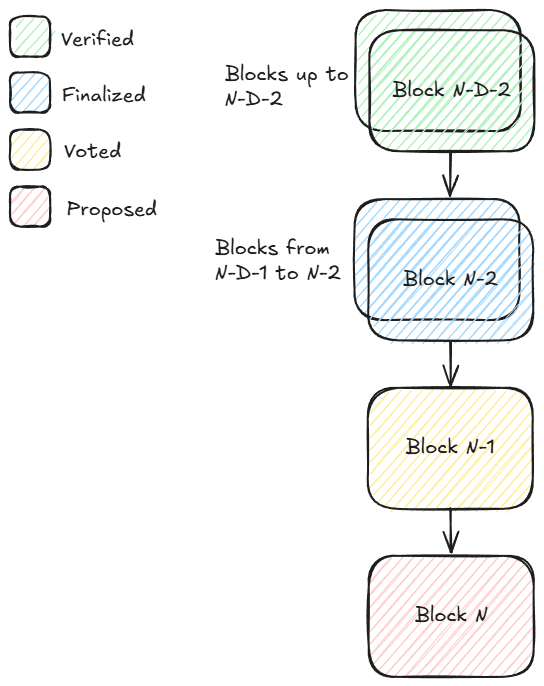
- Proposed: The current block being shared by the leader.
- Voted: The previous block that has received enough votes.
- Finalized: Two blocks behind the proposal — the chain commits here based on MonadBFT.
- Verified: The latest block with an accepted Merkle root from D blocks ago.
By decoupling consensus from execution, Monad transforms a traditional bottleneck into a throughput advantage. Execution runs in parallel, not in the critical path — enabling faster, scalable, and deterministic state updates. With speculative execution, delayed Merkle validation, and full block-time utilization, Monad offers lower latency and a smoother experience — without sacrificing decentralization. This is what asynchronous execution looks like when done right — fast, secure, and future-proof.
-
Optimistic Parallel Execution: More Throughput, Same Determinism
In Ethereum, transactions are processed sequentially to avoid state conflicts. While this guarantees consistency, it severely underutilizes modern CPUs and handicaps the throughput. Monad takes a fundamentally different route: it runs transactions in parallel, assuming they won’t conflict — and only re-validates results at the time of commitment. This model enables massive scalability without sacrificing correctness.
To understand Monad’s architecture, it's crucial to distinguish between execution and commitment:
- Execution is when transactions are actually run to simulate their effect on the blockchain state — like updating balances or contract storage. This often begins before finality is reached, based on the assumption that the block will likely be finalized. This is what we refer to as speculative execution.
- Commitment is when the results of execution are officially applied to the blockchain state. This happens after the block is fully finalized, ensuring that every node agrees on both the transaction order and the resulting state.
Input/Output Tracking and Conflict Resolution
As Monad executes transactions in parallel, it tracks:
- Inputs — the exact storage slots a transaction reads (e.g., account balances or contract mappings).
- Outputs — the slots it writes to or modifies.
This fine-grained tracking at the slot level is crucial for detecting conflicts between transactions — allowing Monad to know exactly when a transaction depends on a piece of state that may have changed. In other words, it is to ensure that none of the inputs have changed since the last execution, or else the transaction has to be re-executed with regard to the updated state。
Example: Resolving Conflicts Between Transactions
Imagine a block contains two transactions:
- Transaction 1: Reads and updates the balance of account A (e.g., receives funds from B).
- Transaction 2: Also reads and updates the balance of account A (e.g., sends funds to C).
If these two are executed in parallel and Transaction 2 starts before Transaction 1 finishes, it may read stale data — an outdated balance for account A. This can lead to incorrect execution.
Monad’s conflict resolution mechanism solves this by comparing:
- The inputs used by Transaction 2
- Against the outputs of earlier transactions like Transaction 1
If any overlap is detected — meaning a storage slot read by Transaction 2 was modified by Transaction 1 — then Transaction 2 is re-executed using the updated state. This guarantees that even in parallel execution, the final outcome is equivalent to fully serial processing.
Performance Optimizations: Aggressive Caching
To make optimistic parallel execution fast and practical, Monad applies several low-level optimizations that dramatically reduce overhead and improve efficiency.
Re-executing a transaction after detecting a conflict might sound expensive — but in Monad, it’s typically cheap. That’s because most of the data a transaction relies on (its inputs) is likely still stored in fast-access memory from the first execution.
Only when a re-execution accesses new code paths or different storage slots does it need to reach back to disk. Otherwise, it simply reuses what’s already in RAM, significantly reducing I/O overhead. Even heavyweight operations like cryptographic signature verification or hashing aren’t repeated — Monad reuses those results from the original execution.
This aggressive caching ensures that retries are lightweight and don’t stall performance, even when conflicts do occur.
-
MonadDB: A Purpose-Built Storage Engine for Parallel Execution
High-throughput parallel execution doesn’t mean much if your storage layer can’t keep up. In Ethereum today, one of the biggest performance bottlenecks isn’t computation — it’s state access. Every transaction must read and write to disk-stored state, which includes account balances, contract storage, and mappings. Ethereum, for example, stores its verifiable state using a Merkle Patricia Trie (MPT), but then embeds that structure inside general-purpose databases like LevelDB or PebbleDB. This introduces double indirection and slows everything down:
- Step 1: Query the external database to find a trie node.
- Step 2: Load that trie node into memory.
- Step 3: Read the node to get the next key in the path.
- Step 4: Repeat steps 1–3 for every level in the trie until you reach the desired state value (like a token balance or contract variable).
Each of these steps can trigger a separate disk read, which is slow compared to memory access because the trie is deeply nested and each node is stored separately inside the external database, even a single state access might result in 16–32 separate lookups on disk.
As general-purpose databases weren’t designed for blockchain-specific access patterns or the demands of multi-threaded execution, even if your execution engine can process thousands of transactions in parallel, performance will stall if it’s backed by a slow, single-threaded storage layer. Thus, there’s a need to optimise the storage layer in order to have ultra-high throughput for layer
MonadDB eliminates this inefficiency by storing Merkle Patricia Trie (MPT) natively — directly on disk and in memory — without embedding MPT in a general-purpose database. The result is drastically faster lookups, lower latency, and fewer redundant reads. State access becomes more aligned with how Ethereum logically processes storage, but without Ethereum’s overhead.
Asynchronous I/O Without Blocking Execution
To support Monad’s optimistic parallel execution, MonadDB is designed for high concurrency from the ground up. Unlike traditional databases, it uses asynchronous I/O through Linux’s io_uring, allowing the system to issue thousands of storage requests without blocking execution threads. This means while some transactions are fetching state, others can continue executing — keeping all CPU cores fully utilized, not bothered by disk I/O.
This is critical: disk I/O is by orders of magnitude slower than memory or CPU. For example, fetching a value from disk — such as an account balance or contract variable — can take hundreds of microseconds, while the CPU operates in nanoseconds. In traditional synchronous systems, this means the CPU would sit idle waiting for the disk read to finish. This is the inefficiency.
MonadDB avoids this with asynchronous I/O. Suppose Alice is sending tokens to Bob. To process this transaction, the system needs to fetch Alice’s balance from disk. In a synchronous model, execution would pause until the data is retrieved. But MonadDB queues the read in the background and meanwhile continues executing other independent transactions — say, Charlie interacting with a DeFi contract. Once Alice’s balance is loaded, it’s instantly used to finalize her transaction. This model keeps the CPU saturated with work and maximizes throughput.
By contrast, many traditional Ethereum clients like Nethermind or Geth rely on memory-mapped storage (mmap) to access state. This approach is inherently blocking — if a transaction needs a state that isn’t already in memory, the CPU must pause and wait for the data to be loaded from disk. Even if other tasks don’t depend on that data, they just pause and wait, creating idle CPU cycles and underutilized hardware. MonadDB avoids this trap entirely by using asynchronous I/O (via io_uring), allowing the CPU to continue executing unrelated tasks while state is fetched in the background — maximizing throughput and keeping all hardware resources fully utilized.
Filesystem Bypass for Raw SSD Performance
Even the most advanced filesystems introduce significant overhead that slows down high-throughput systems. These overheads include
- Fragmentation, which causes files to be split across different disk locations, slowing down reads,
- Block allocation, which introduces delays as the system finds where to store new data
- Metadata management, which adds overhead in tracking file structure and access
- Read/write amplification, which means small logical writes can trigger larger physical writes.
All of these degrade performance, especially under the heavy parallel access patterns of a modern blockchain.
MonadDB avoids all traditional filesystem overhead above by bypassing the OS layer entirely.
Instead of interacting with files through the operating system, MonadDB writes directly to raw block devices — the actual storage hardware (like /dev/sda in Linux). This gives Monad full control over how data is written and laid out on disk, without relying on the kernel’s file and metadata systems.
At the core of this system is MonadDB’s custom Patricia trie indexing, which directly maps blockchain state to disk storage. Each node in the trie corresponds to actual on-disk data, allowing Monad to read and write state without intermediary abstractions. This design ensures that state access is direct, predictable, and real-time.
The benefits of MonadDB’s low-level disk access include:
- No fragmentation, metadata, or file allocation overhead
- Fully sequential writes — ideal for SSDs, reducing write amplification and improving drive lifespan
- Low-latency performance, even at high throughput
For operators, this means MonadDB can be run on either regular files or raw block devices. But for optimal performance — especially under heavy load — direct-to-disk mode is recommended. It ensures Monad can fully unlock SSD bandwidth and sustain high performance as throughput scales.
Every time MonadDB updates the state, it creates a new version of the affected part of the trie. Instead of changing old data, it adds new nodes in the Patricia trie data structure inside the database, while keeping the previous ones untouched. This allows different parts of the system — like the execution engine, consensus mechanism, and RPC layer — to safely read consistent data even while new updates are happening. Because older versions are preserved, the database ensures data consistency without any conflicts.
This versioning is especially useful for node synchronization. When a new node joins the network, it doesn’t need to replay everything from the beginning. Instead, it can quickly download a recent version of the state and catch up using these saved snapshots. This makes syncing faster, safer, and much more efficient — even as the network handles high throughput.
Overall, MonadDB is purpose-built to match the demands of a high-performance Layer 1, enabling fast, parallel state access without modular complexity or centralized trade-offs.
Latest writing
Get In Touch
If you have thoughts, project updates, or feedback to share, please reach out via email. We encourage all submissions to include a detailed description and the latest developments.
general@velocity.capital