Published on: Jun 16, 2025
by: Velocity Capital
Building Trustworthy AI Systems: How Mira Eliminates Hallucinations and Bias
In every AI cycle, we’ve seen flashy demos and viral bots — but beneath the surface, two critical problems keep holding the industry back: trust and autonomy. Most AI agents today are just wrappers around large models like ChatGPT — they can generate content, but they can’t be trusted to act. They hallucinate, break under pressure, and need constant human oversight. Mira AI is here to enforce their vision that AI models are not just about being powerful but reliably beneficial. In fact, it has already shown strong real-world traction:
- 3M+ users, including 500K daily active users (DAUs)
- 2 billion tokens processed daily (i.e, 8 million images or 50 days of uninterrupted video)
- 90% error reduction, pushing accuracy rate from ~70% to nearly 98%, with 99%+ on the horizon
- Adopted across both Web2 and Web3, Mira is now empowering critical systems for leading organizations like Delphi Digital and other top tech companies.
In this article, we’ll break down the two biggest challenges in AI today, how harmful they are across industries, and how Mira’s architecture solves them — from privacy-preserving consensus to on-chain verification and beyond.
Problem 1: Hallucinations — When AI Sounds Right but Gets It Wrong
We’ve all seen it — AI chatbots may confidently tell you a law was passed in 2023, when in fact it wasn’t; or they cite a scientific study that seems credible but doesn’t exist at all. These aren’t just quirky glitches — they’re part of a well-documented phenomenon in AI called hallucination.
These hallucinations aren’t lies in the traditional sense. The AI isn’t trying to mislead you. Instead, it’s doing exactly what it was designed to do: generate language that sounds plausible, based on patterns it has learned from massive amounts of text data. In other words, current AI models tend to think in a probabilistic manner, and will probably not give you completely identical answers if you ask them the same question twice or even thrice. When that data lacks clarity, or the question falls into a gray area, the AI doesn’t admit uncertainty — it will make guesses confidently, which can be surprisingly persuasive that makes their answers misleading.
At the heart of this issue is how modern AI systems are built. LLMs don’t store factual knowledge like a database or verify claims like a researcher, and thus they don’t truly "understand" anything; instead they’re engineered to predict the next word in a sentence by identifying statistical patterns across billions of documents — books, articles, webpages, forum posts — everything from encyclopedias to Reddit threads.
Sometimes, even though the answer is factually wrong, the output doesn’t look like a failure. As LLMs aren’t grounded in truth, when they encounter a question with no clear answer — or a topic underrepresented in their training, they just generate something that fits the linguistic pattern and semantic context, even if it’s fabricated. Most importantly, LLMs can get the very basic things right, gaining our trust, so that when we do not know the answer, we just assume it is right. That's what bites us—the tone may be professional; the structure may be flawless. But the information? Completely fictional.
Ask: “What was the name of the climate agreement signed in London in 2021?”
AI might respond: “The London Climate Accord of 2021.”
Sounds right. Sounds official.
It just Doesn’t exist.
This is hallucinations: outputs look real, but they’re actually made-up fabrications masquerading as facts. It’s this polish of the delivery that makes hallucinations so dangerous, especially for users who are working on serious tasks and repose trust and confidence in the outputs of AI models. Another way to explain this issue is that AI works like a game of telephone, and at some point it picks a wonky next token and everything can go downhill—it just builds on that wrong fact.
Precision vs. Accuracy: Why AI Gets Confidently Wrong
This kind of failure is referred to as a precision error — a situation where the AI gives you a highly detailed and confident answer that turns out to be utterly factually incorrect.
To fully understand the problem, we need to unpack two important concepts: precision and accuracy.
- Precision refers to how specific, detailed, and exact an answer is.
- Accuracy refers to whether that answer is actually correct in the real world.
AI systems today are often very precise, but not reliably accurate. And that mismatch is exactly why hallucinations matter — because in fields like healthcare, law, finance, or journalism, factual accuracy isn’t optional. It’s necessary, essential and non-negotiable.
Hallucinations in the Wild: Real-World Consequences of Confidently Wrong AI
AI hallucinations aren’t just a theoretical risk. They’re already causing serious issues across critical sectors:
-
Healthcare: Transcribing Patients into Danger
A recent study from Cornell and the University of Washington found that OpenAI’s Whisper model hallucinated in 1.4% of medical transcriptions. It sometimes invented entirely fake medications like “hyperactivated antibiotics,” or inserted inappropriate racial remarks — even when those weren’t present in the original audio.
Worse yet, some commercial platforms using Whisper delete the original audio after transcription—leaving 30,000+ clinicians across 70+ healthcare institutions without a way to verify what was actually said. In medicine, even a 1% hallucination rate can contaminate correct treatment completely, causing irreversible harm.
-
Law: Fictional Case Law, Real Liability
In the legal world, the stakes are equally high. A Stanford study testing legal research tools like Lexis+ AI and Westlaw’s AI-Assisted Research found hallucination rates of 17% and 34%, respectively, despite these tools being marketed as “hallucination-free” thanks to the retrieval-augmented generation (RAG) systems.
One notable example: an AI legal assistant confidently cited a supreme court precedent that had already been overturned, offering outdated legal standards vis-a-vis the current law. In another case, it hallucinated an entire statutory provision that doesn’t exist. When lawyers rely on AI for drafting, such hallucinations can result in malpractice, false arguments, and even court sanctions.
-
Travel: When Chatbots Promise the Impossible
In 2022, Air Canada’s chatbot assured a grieving passenger that he could apply for a bereavement refund after booking a full-price flight. When the passenger followed up, the airline denied the request and claimed the chatbot was “a separate legal entity responsible for its own actions.” But the British Columbia Civil Resolution Tribunal disagreed. It ruled that Air Canada was fully liable for what its AI said and did, ordering the company to pay $812.02 in damages. This ruling has set a precedent for how companies are held accountable for AI-generated misinformation.
-
Science: Fabricating Research Out of Thin Air
Meta’s language model Galactica, designed to generate scientific papers and literature reviews, was shut down just three days after its launch, after it was found to fabricate the research citations and create fake sources that looked real, along with invented studies and made-up scientific facts that sounded convincing, yet were completely fabricated. In science, where accuracy and peer review matter more than anything, this wasn’t just a minor glitch. False information dressed up as real research can mislead scientists, distort academic understanding, and damage trust in the field.
All these incidents above are some of the biggest headwinds against the mass adoption of AI. AI models are not just about being powerful, but reliably beneficial. As AI becomes more common in high-stakes fields like healthcare, law, travel, and science, its habit of making things up becomes a growing concern. From chatbots inventing refund rules to medical transcription tools making up fake medications, these real-world failures highlight a deeper flaw: AI often can’t tell the difference between what sounds right and what is actually true.
Problem 2: Built-In Bias — How Centralized AI Reflects a Single Worldview
Today’s AI landscape is centralized. The most powerful models are built and controlled by just a few companies, mostly based in the U.S. and China. The teams behind the scene are homogenous and often share similar backgrounds and cultures, which are then probably embedded directly into model architecture, training data, safety policies that reflect their shared view of the world. The teams’ values seep into AI models via their decisions on what to train the model on and what guardrails to build.
The same teams who build these AI systems are also the ones deciding what’s safe, fair, or acceptable. This gives small groups of people the power of reshaping how billions of people think about things, by conveying their values via people’s interaction with AI. As a result, cultural diversity and heterogeneity are in jeopardy as AI is growing large, as bias comes in.
Bias isn’t a small bug or rare mistake — it’s a built-in issue that sits at the center of how AI systems are designed and governed today.
Some problems with AI, like hallucinations, can be fixed using techniques like fine-tuning or retrieval from trusted sources. But bias is different. It’s not an occasional error, but a systemic one. It shows up in the data that gets included, the ideas that are highlighted, and the voices that are left out. And unlike hallucinations, which are often easy to spot, bias usually goes unnoticed — and unchallenged.
So what exactly is bias?
Bias is a kind of filter — a lens that AI applies to everything it produces. It affects how a question is understood, what kind of answer is given, and which facts or opinions are prioritized. Over time, this filter will become a big source of distortion of perception and truth. And this isn’t just a theory — it’s already happening:
- When AI underrepresents voices from the Global South: that’s bias.
- When it favors specific political ideologies or cultural norms: that’s bias.
- When it presents one narrative as “neutral” and paints alternatives as “radical”: that’s bias.
These are active, ongoing failures already reshaping public discourse, education, healthcare, justice, and governance — without public scrutiny or democratic oversight.
The real danger? Bias doesn’t break the system — it becomes the system.
Real-World Example of Political Bias in Language Models: Policy Recommendations for the EU
One of the clearest signs that today’s AI models reflect narrow worldviews comes from a recent study focused on how LLMs respond to political questions. Researchers tested 24 leading models by asking them to advise on policies specifically for the European Union across a wide range of topics — including housing, healthcare, civil rights, immigration, and climate policy.
The outcome was striking: over 80% of the models’ responses leaned towards the left, i.e. the majority of them supported ideas like stronger government regulation, wealth redistribution, climate-forward energy policies, open immigration, and expanded welfare systems. Meanwhile these models regularly ignored more conservative or right-leaning perspectives, such as free market policies, limited government, energy independence, and individual responsibility. Interestingly, while mainstream AI models like GPT, Claude, Gemini, and LLaMA consistently delivered responses aligned with progressive or center-left ideologies, base models (those that hadn’t been fine-tuned for mass deployment) were far more balanced in their output.
To dig deeper, researchers trained two additional models with explicit ideological leanings: one left-leaning and one right-leaning. The contrast in their responses showed clearly how model behavior shifts based on fine-tuning choices. Take a look at the chart below. It maps the political bias in model responses for EU policy questions. Each row represents a topic like energy or education. Each column shows a different model. Red signals left-leaning answers, blue signals right-leaning ones, and yellow represents neutral or centrist views.

The takeaway is clear: the foundational models themselves are inherently balanced. The slant toward one political ideology often comes during fine-tuning, when companies shape the model to match internal ideas of what’s “safe,” “aligned,” or “responsible,” with some value alignment not just addressing the AI security concerns, but also embedding some ideologies over others. This shift isn’t random. It reflects deliberate design choices — and it directly impacts how AI users experience information.
To truly fix AI’s issues with hallucinations and bias, any solution must be built on the right foundation. A trustworthy system needs core principles like transparency, fairness, privacy, and accountability at its core — not just as features, but as defaults.
That’s exactly what Mira AI is designed around.
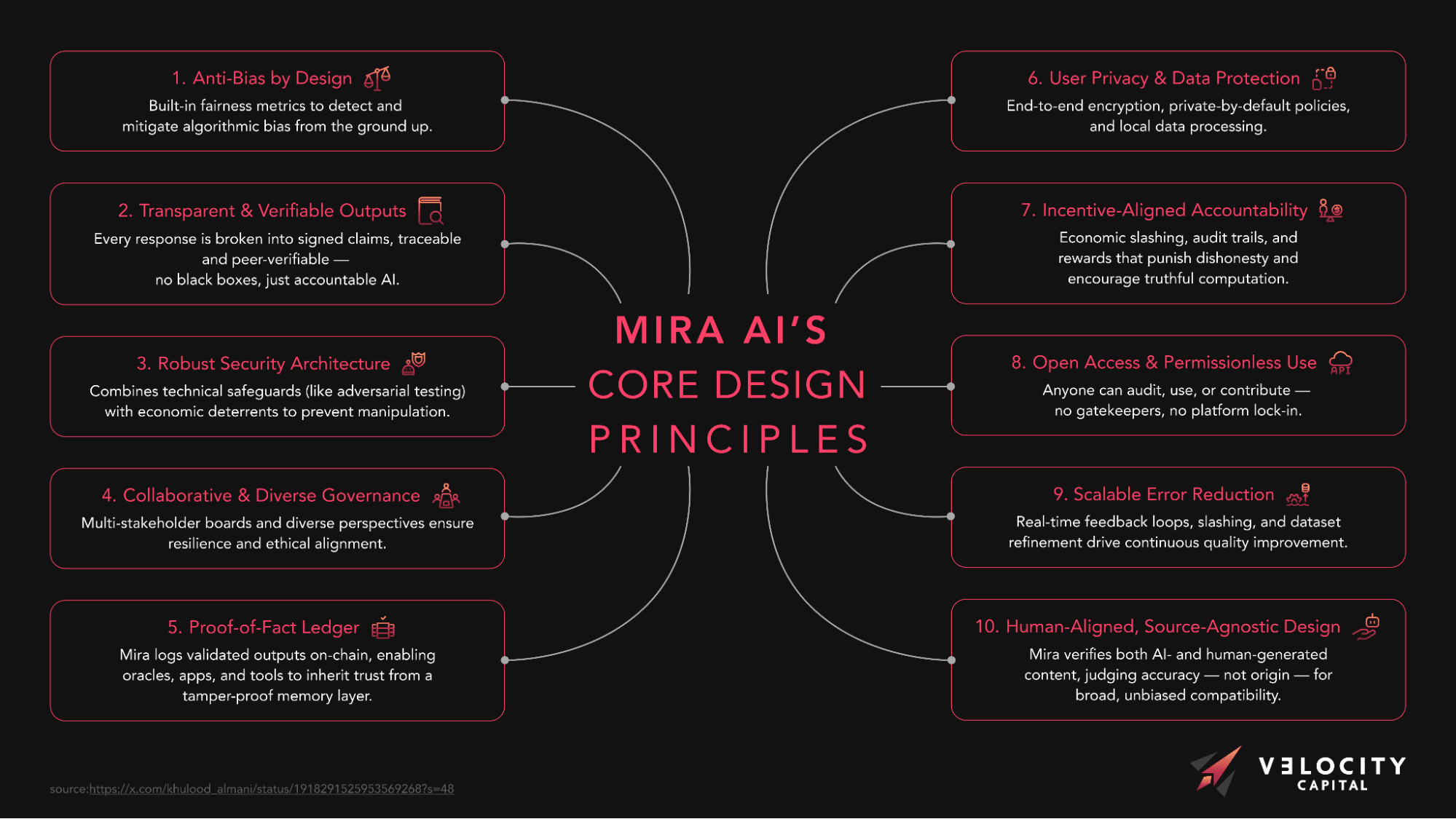
Mira AI addresses this challenge by introducing a decentralized, trustless verification system for AI-generated content — one that combines collective model consensus, cryptoeconomic incentives, and privacy-first design to ensure outputs are both reliable and secure. Instead of relying on one model or a central authority, Mira uses a network of independent AI models that cross-verify each others’ outputs via a consensus mechanism. This ensures that hallucinated facts get filtered out and individual model biases are balanced, making the final answer significantly more reliable.
Mira’s Solution at a Glance
Mira can be regarded as a verification layer for AI: whenever an AI model produces output tokens (an answer, a piece of text, etc.), Mira’s network starts verifying the validity of outputs before reaching to end-users, by way of breaking the output into smaller factual claims and having multiple AI validators cross-check each claim. Only when independent validators reach a consensus that every claim is correct and unbiased will the overall output be considered verified and delivered to users, accompanied by a proof of validity.
In essence, multiple minds (AI models) must agree on an answer, rather than trusting a single model’s response. This decentralized consensus approach dramatically can improve the accuracy. For example, using an ensemble of models this way has been shown to cut AI error rates on complex tasks from around 30% down to roughly 5%, with further reductions as the system scales toward sub-0.1% error rates.
How Mira Verifies an AI Output
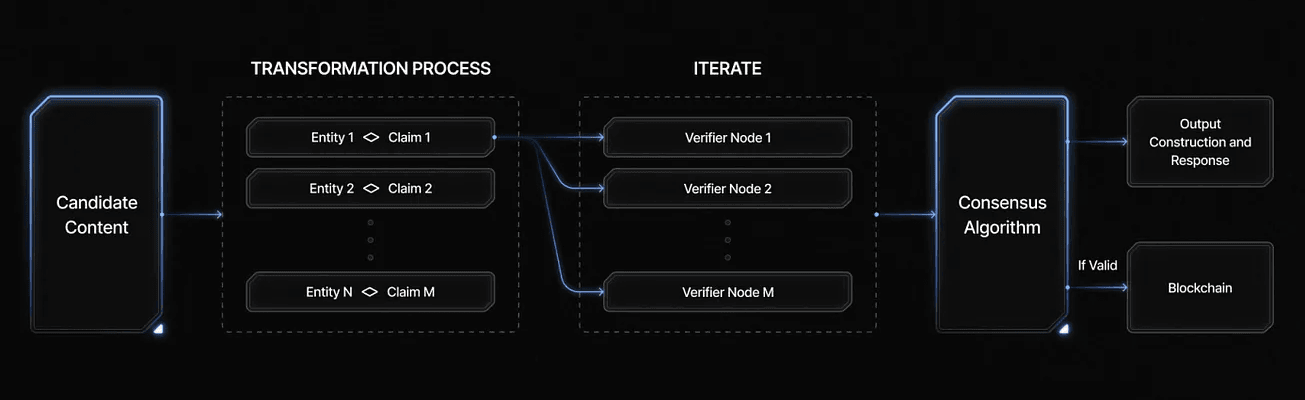
To illustrate Mira’s process, consider an example. Suppose an AI model generates the statement: “The Earth revolves around the Sun and the Moon revolves around the Earth.” A single AI might do this confidently – and in this case it happens to be correct. But how would Mira’s decentralized system verify it?
Breaking into claims: First, Mira’s protocol splits this compound statement into individual factual claims. In this example, the two claims are:
(1) “The Earth revolves around the Sun” and
(2) “The Moon revolves around the Earth.”
Breaking down content this way is essential because if you gave the entire sentence to different AI models to verify, each model might latch onto a different aspect of the statement (one model might only verify the first part while another focuses on the second). That could lead to inconsistent or incomplete verification.This ensures that every model is verifying the exact same statement rather than interpreting different parts.
- Distributed verification: Once the output is broken into multiple claims, Mira distributes these claims to a network of validator nodes. Each node is run by an independent operator and contains an AI model (potentially different models on different nodes) that will evaluate respective claims. In our example, Claim (1) goes out to a set of validator nodes, and Claim (2) to another set. The nodes work in parallel, each independently determining whether the claim is true or false according to its AI model’s knowledge. The diversity of models helps prevent errors caused by hallucinations or bias.
- Reaching consensus: The Mira network then collects the votes or responses from the validators for each claim. If the required number of validators (a consensus threshold) agree a claim is true, that claim is considered verified. For simple cases like “The Earth revolves around the Sun,” a basic majority is usually enough—and we’d expect full agreement. But for high-stakes content like medical or legal information, users can configure stricter thresholds, requiring almost unanimity from all validators. If a claim falls short—say validators are split—it’s flagged as unverified. This helps catch hallucinations, like a false claim such as “the Earth is flat,” which wouldn’t reach consensus and would be blocked or corrected.
- Cryptographic certification: Once all the claims in an output are verified by consensus of the nodes, Mira combines those verified claims back together into the final output content. At this point, the network issues a cryptographic certificate to attest that the output has been verified. This certificate is essentially a tamper-proof, proof of validity that serves as a trust badge to confirm that the entire statement has been independently verified and trustworthy, by providing three key perspectives: (1) what is the fact, (2) which models helped validate it, and (3) how the consensus is formed. It includes a digital signature or record of the validators’ agreement, and it is written on a blockchain. In our example, after both claims (1) and (2) are validated by consensus, a certificate is created to confirm that “The Earth revolves around the Sun and the Moon revolves around the Earth” has already been verified by the Mira network.
Economic Security: Hybrid PoW/PoS and Honest Incentives
One of Mira’s novel features is its hybrid Proof-of-Work (PoW) / Proof-of-Stake (PoS) security model. In blockchain terminology, Proof-of-Work requires computational work and Proof-of-Stake requires participants to put some economic value at risk (stake) to incentivize honest behavior. Mira leverages elements of both:
- Staking (PoS element): Validator nodes must stake assets (e.g. Mira network tokens) as collateral before participating in Mira’s network. This stake is locked up and can be slashed (forfeited) if the node behaves dishonestly or violates the rules. A malicious actor would risk losing a lot of money if they try to push through incorrect answers and get their stakes slashed. On the flip side, honest validators are rewarded for each claim they verify correctly in alignment with the consensus.
- Proof of Work: Validating AI Through Real Computation: In Mira’s network, validators aren’t just approving transactions — they’re running real AI model inferences, such as processing user queries or generating outputs. This consumes significant GPU power and electricity, making it a genuine form of computational work. Just like Bitcoin miners prove their contribution by solving cryptographic puzzles, Mira validators prove theirs by completing AI tasks. This computation acts as their proof of contribution, forming the foundation of Mira’s Proof-of-Work layer.
Privacy Preservation: Sharding and Cryptographic Safeguards
When multiple independent nodes are verifying pieces of a user’s content, one might worry about privacy: how do we ensure that sensitive user data in prompts aren’t exposed to strangers’ machines? Mira’s architecture addresses this via content sharding, randomized task assignment, and cryptographic protections designed to keep user data confidential all the way through, even while it’s being verified.
The process starts with sharding. Instead of exposing complex data in full, the network breaks down each piece of customer content into small, structured entity-claim pairs—simple statements like “X causes Y” that represent individual facts or relationships. These pairs are then randomly sharded across different nodes, so no single node can reconstruct the full inputs. This ensures that individual node operators never see the complete picture, safeguarding customer privacy without compromising the integrity of the verification process. In addition, the system is designed to support adjustable privacy levels: for highly sensitive content, it can increase the number of shards or make each shard smaller, enhancing privacy in exchange for a modest increase in computational effort.
To further protect user data, Mira employs randomized task assignment and rotation of verification roles. Each content shard is sent to a randomly selected validator, and no node knows which other nodes are handling related shards from the same content. This unpredictability makes targeted collusion extremely difficult: even if a malicious operator wanted to piece together user data, they wouldn’t know who to coordinate with. Moreover, since validators must stake assets to participate, controlling a large number of nodes (enough to capture all shards of a single input) becomes economically unfeasible. This random sharding and assignment strategy ensures that each validator sees only a tiny fragment of content, mixed with fragments from many different users, making it virtually impossible to reconstruct or target specific data.
Finally, Mira’s privacy model is further strengthened by multiple layers of protection, including the use of cryptographic protocols and secure computation techniques. Verification responses from validator nodes remain private until consensus is reached, ensuring that no intermediate information is leaked during the process. Once consensus is achieved, the network generates a cryptographic verification certificate that includes only the essential verification details — a data minimization approach that proves the correctness of the output without exposing any sensitive content. This certificate can be publicly verified, and reveals nothing beyond a cryptographic hash of the result.
Conclusion: Mira AI Is the Trust Layer of AI
Mira AI isn’t just solving hallucinations and bias, but redefining what trustworthy AI looks like. By combining decentralized consensus, on-chain verification, privacy-preserving design, and incentive-aligned security, Mira delivers outputs that are accurate, unbiased, and provably correct. It’s a system built not just to assist, but to act — confidently, autonomously, and reliably.
And this is just the beginning. Mira’s roadmap points toward a future where verification is built into the way AI creates its answers from the start. From validating complex content like code and multimedia to building an on-chain memory of verified knowledge, Mira is laying the foundation for AI systems that are not only powerful, but more reliably beneficial.
Latest writing
Get In Touch
If you have thoughts, project updates, or feedback to share, please reach out via email. We encourage all submissions to include a detailed description and the latest developments.
general@velocity.capital